All Categories
Featured
Table of Contents
What is very important in the above contour is that Entropy provides a higher worth for Info Gain and hence create even more splitting compared to Gini. When a Decision Tree isn't complicated sufficient, a Random Woodland is usually used (which is absolutely nothing more than several Choice Trees being expanded on a part of the information and a final majority voting is done).
The number of clusters are established making use of an elbow joint curve. Recognize that the K-Means algorithm maximizes locally and not worldwide.
For even more information on K-Means and other forms of without supervision knowing algorithms, have a look at my other blog site: Clustering Based Without Supervision Understanding Neural Network is one of those neologism algorithms that every person is looking towards nowadays. While it is not feasible for me to cover the elaborate information on this blog, it is necessary to understand the basic mechanisms along with the concept of back breeding and vanishing slope.
If the case research need you to develop an expository version, either pick a different model or be prepared to discuss how you will certainly discover exactly how the weights are contributing to the final outcome (e.g. the visualization of hidden layers throughout photo acknowledgment). Ultimately, a single version might not accurately figure out the target.
For such situations, a set of numerous versions are used. One of the most usual method of reviewing model efficiency is by computing the portion of documents whose documents were predicted accurately.
Below, we are seeking to see if our design is as well intricate or not complicated sufficient. If the design is simple enough (e.g. we decided to make use of a linear regression when the pattern is not straight), we finish up with high prejudice and reduced variation. When our version is as well complicated (e.g.
Machine Learning Case Studies
High variation because the result will VARY as we randomize the training data (i.e. the design is not really secure). Now, in order to identify the version's complexity, we make use of a learning contour as shown listed below: On the learning contour, we differ the train-test split on the x-axis and calculate the accuracy of the model on the training and validation datasets.
Faang Interview Prep Course

The further the contour from this line, the higher the AUC and better the design. The highest possible a design can obtain is an AUC of 1, where the contour forms an appropriate tilted triangle. The ROC contour can also help debug a model. If the lower left edge of the contour is more detailed to the arbitrary line, it implies that the version is misclassifying at Y=0.
If there are spikes on the contour (as opposed to being smooth), it indicates the version is not steady. When handling fraudulence designs, ROC is your friend. For even more information read Receiver Operating Attribute Curves Demystified (in Python).
Data scientific research is not simply one area yet a collection of fields used together to build something distinct. Data scientific research is simultaneously maths, statistics, analytic, pattern searching for, communications, and organization. As a result of how broad and interconnected the field of data scientific research is, taking any type of step in this area may seem so complicated and complex, from attempting to discover your method with to job-hunting, looking for the right duty, and ultimately acing the interviews, however, despite the intricacy of the area, if you have clear actions you can comply with, getting into and obtaining a task in information science will not be so puzzling.
Information science is everything about maths and statistics. From probability concept to straight algebra, maths magic allows us to recognize information, locate patterns and patterns, and build formulas to forecast future data scientific research (data science interview preparation). Math and statistics are vital for data science; they are constantly inquired about in information science meetings
All skills are used everyday in every information scientific research project, from data collection to cleaning up to exploration and evaluation. As soon as the job interviewer tests your ability to code and consider the various algorithmic troubles, they will certainly give you data scientific research problems to evaluate your data handling abilities. You frequently can pick Python, R, and SQL to tidy, explore and evaluate an offered dataset.
Practice Makes Perfect: Mock Data Science Interviews
Artificial intelligence is the core of many data scientific research applications. You may be writing maker learning algorithms just often on the work, you require to be really comfy with the standard maker learning formulas. In addition, you require to be able to suggest a machine-learning algorithm based on a specific dataset or a certain trouble.
Excellent resources, consisting of 100 days of artificial intelligence code infographics, and walking via an artificial intelligence trouble. Recognition is just one of the primary actions of any type of information scientific research project. Guaranteeing that your version acts appropriately is crucial for your business and customers because any kind of mistake may create the loss of cash and resources.
Resources to assess recognition include A/B testing meeting inquiries, what to prevent when running an A/B Test, type I vs. type II mistakes, and standards for A/B tests. Along with the concerns regarding the certain building blocks of the field, you will always be asked basic information science concerns to examine your ability to put those building obstructs with each other and create a total project.
The data science job-hunting process is one of the most challenging job-hunting processes out there. Looking for work functions in information science can be tough; one of the main reasons is the uncertainty of the role titles and descriptions.
This ambiguity just makes preparing for the interview much more of a trouble. Besides, how can you plan for a vague function? By practicing the fundamental structure blocks of the area and then some general inquiries about the different algorithms, you have a robust and powerful combination ensured to land you the job.
Preparing for data scientific research meeting inquiries is, in some respects, no different than getting ready for an interview in any various other market. You'll look into the company, prepare answers to usual interview questions, and review your profile to utilize throughout the interview. However, getting ready for a data scientific research meeting entails more than getting ready for inquiries like "Why do you believe you are received this position!.?.!?"Information scientist meetings include a great deal of technological subjects.
Comprehensive Guide To Data Science Interview Success
, in-person interview, and panel meeting.
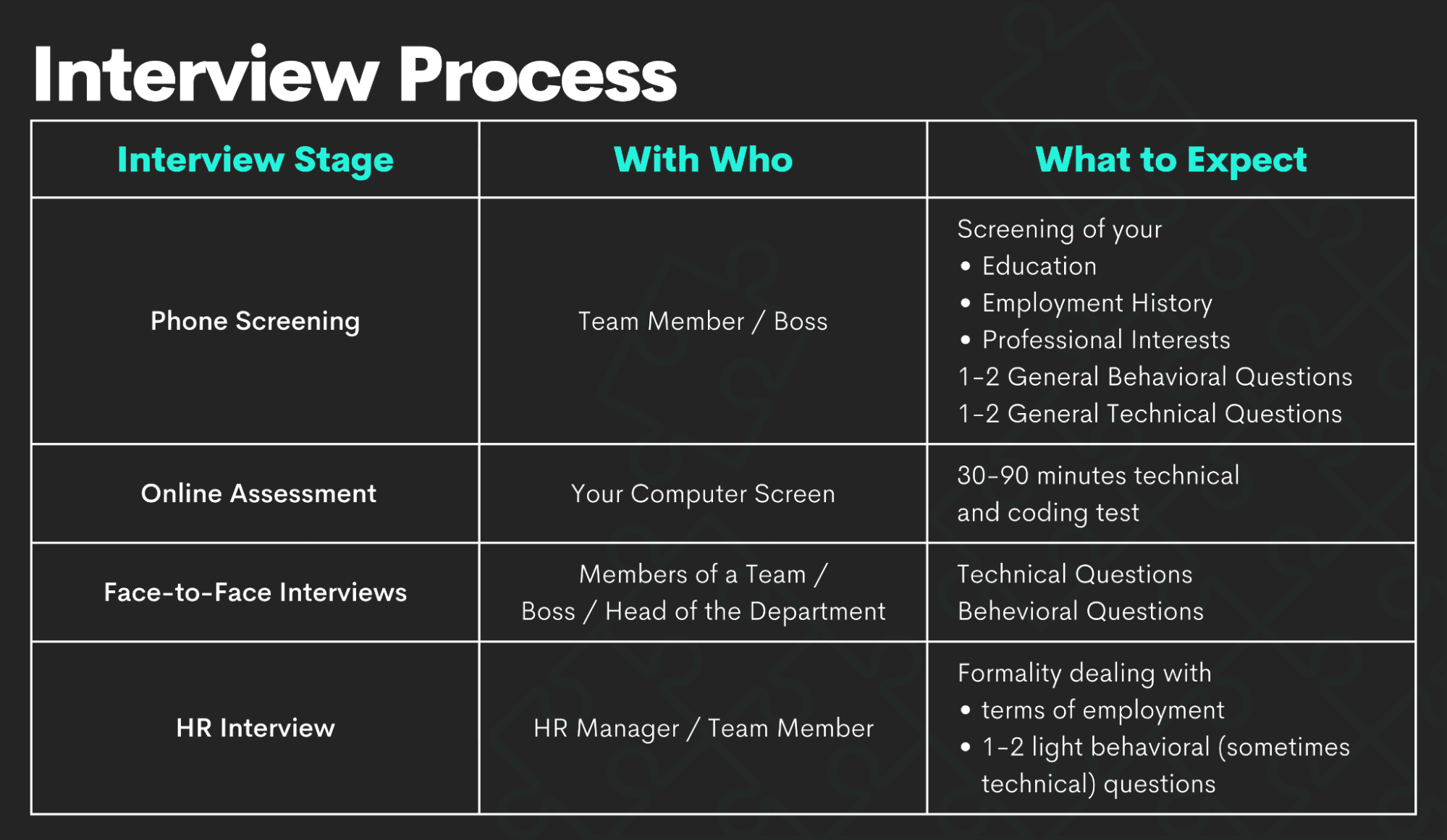
A certain method isn't necessarily the very best just since you have actually utilized it in the past." Technical skills aren't the only type of data scientific research interview inquiries you'll encounter. Like any kind of meeting, you'll likely be asked behavior concerns. These questions aid the hiring manager comprehend how you'll utilize your abilities at work.
Here are 10 behavioral concerns you may experience in an information researcher interview: Tell me about a time you used information to bring about alter at a task. What are your pastimes and rate of interests outside of data scientific research?
Understand the different types of meetings and the total procedure. Dive right into data, probability, hypothesis screening, and A/B screening. Master both standard and advanced SQL questions with practical troubles and simulated interview inquiries. Make use of crucial collections like Pandas, NumPy, Matplotlib, and Seaborn for data adjustment, analysis, and fundamental machine discovering.
Hi, I am currently planning for an information science meeting, and I have actually stumbled upon a rather difficult concern that I can make use of some help with - mock interview coding. The inquiry entails coding for an information scientific research trouble, and I think it calls for some innovative skills and techniques.: Given a dataset including details about consumer demographics and acquisition background, the job is to predict whether a customer will make an acquisition in the next month
Data Engineer Roles And Interview Prep
You can't execute that activity at this time.
Wondering 'Exactly how to get ready for information science meeting'? Keep reading to discover the solution! Source: Online Manipal Analyze the job listing completely. Visit the business's official internet site. Analyze the competitors in the market. Recognize the company's worths and culture. Investigate the business's most current accomplishments. Find out about your possible job interviewer. Prior to you study, you must know there are particular kinds of interviews to prepare for: Interview TypeDescriptionCoding InterviewsThis interview examines expertise of numerous topics, consisting of device knowing methods, practical information extraction and control obstacles, and computer technology principles.
{kind=link}
Latest Posts
How To Optimize Machine Learning Models For Technical Interviews
How To Prepare For A Software Engineering Whiteboard Interview
How To Solve Case Study Questions In Data Science Interviews